 English
English  Français
Français  български
български  Deutsch
Deutsch 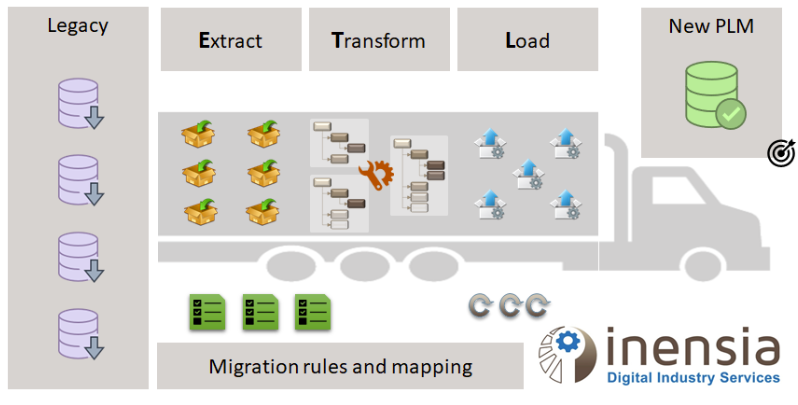
- What is a PLM data migration?
To illustrate it in a simple way, migrating data is like making a removal. In fact, you are changing the place where they are stored. For sure, this analogy finds its limits insofar as data adaptations are made. Let’s say that it is as if you were using migration rules during the moving out. For example, your plates are separated: half of them are colored in red; the other ones are now stored in the lunchroom.
This activity is almost always related to a new PLM solution implementation. That is why we are taking the opportunity to gather product data sources. As business needs and working organization can now be different, we must make the data usable by adjusting them to fit the new tools and processes.
We can now say that data migration is a process to move and adjust data from sources into targets. This can be also called ETL (EXTRACT from legacy applications, TRANSFORM by applying defined rules, LOAD into new applications).
Beyond the concept of data migration, practice and experience are essential assets to succeed.
- How to define migration strategy?
Choosing the right migration strategy is really at the heart of this piece of work. It depends on the following questions:
o Are source applications to be maintained or not?
o What is the data criticality for the whole company?
o Is there a need to live access to the history?
o Is it necessary to keep track of data validation steps?
o Is there a regulatory rule in terms of data retention?
Based on the answers, it is possible to then define how source data are moved into new applications or into archives or nowhere. For example, we can consider that:
o The latest version of parts and assemblies are loaded into the new application.
o The previous versions are saved as PDF file into an archive system
o The different approvals (from workflows) are stored as a table in the new application.
o And many other similar rules fitting both the business needs and constraints.
Underestimating migration strategy activity can lead to major planning and cost impacts for your PLM program.
- When is the right moment to start migration?
A new implementation of the PLM solution leads, among other things, the migration activities. Whatever is the global project management methodology (Agile, Waterfall, V-Cycle, …), data migration is usually part of critical path. Due to that, this activity must start at an early stage. While the implementation team is working on solution requirements, the migration team is working on source data analysis. When the build phase starts, implementation and migration teams must have alignment meetings to synchronize target data model (object types, attributes, …) and data definition (migration rules and mappings).
Similarly, integration testing and data loading tests must be both executed in parallel to check the overall consistency of the solution with migrated data. In the end, key users will then make UATs (Users Acceptance Tests) both on solution and data. The goal is also to test the solution behavior with migrated data and not only with data created from scratch with new solution functionalities.
Even migration activities can be carried out in a different way, some project milestones must be common between solution implementation and data migration. There is no alternative to make sure the solution will be usable at Go Live with already existing data.
Tightly synchronize your migration team with the application team at every step of the PLM program.
- How to be sure loaded data are consistent?
Finally, it is mandatory to validate that loaded data are compliant with the newly implemented solution while remaining consistent with previously existing data (data as they were in source applications). To do so, we can define and use loading logs and migration metrics to have a first level of validation. An export can also be made to compare loaded data with source data (or data prepared for loading). Doing this can allow additional detection of issues. However, the programs and tools should have to be tested to validate they are running properly. Such comparison can be time consuming also/ like the to generate right export and comparisons tools.
To have an enough good visibility on data quality, we need users ‘expertise because they are pretty well knowing their own data and they can choose right samples to highlight possible issues within the different multiple cases we can find. For sure, it is humanly impossible to check each object. That is why a data sampling is made with randomly selected data even they can be smartly chosen by key users.
Do involve your key users on checking loaded data to get the best possible quality and accuracy.
[*] Product Lifecycle Management is a demarche within a company to support all product data from its inception until its dismantling.
Author: Hervé Duhamel, Inensia Senior Application Architect